Catégorie: "Développement"
OpenCascade : How to make money with free software ?
Avril 11th, 2006I wrote this article 6 mois ago. I was waiting for some stuffs around this. However, it is too late so I release it.
My main concern about free software as a way of doing business is "how do you make money out of it ?".
Unfortunatelly, I still don't see any solution ... Of course, it is possible by selling services, maintenance, help, more (costly) advanced version, side development (usually proprietary) but it is not doing money only on free software/development.
Let's me describe on of the solution that uses Opencascade, a former department of Matra.
They produces for a quite long time (about 10 years) a big project called "Open CASCADE". It is a framework used to modelise, visualise 3D models (and many other things that I hardly understand)... It has an aspect of gas factory ("Usine à gaz" as we say in French) because the size/age/complexity of the project. However, it is a very convenient way of doing 3D (many famous corporations use it).
At work, I am working on a project launched by the BRGM (Bureau de recherche géologique et minière ... the equivalent of the french CNRS but for earth sciences) about 10 years ago. The aim of the project is to provide to geologists and geophysists a way of representing the underground. The corporation where I work is doing the work of adding new features, packaging and selling the software. For this project, we use Opencascade.
My work on this project was to provide a visualisation of drillholes in a 3D space (holes that are dug in the ground to get the geological structure of the underground). Basically, I was supposed to represent a (drunk) worm hole from a serie of points.
I tried many way (from the ugliest to the sharpest) but I found some problems with my favorite. When I used too much points, the framework start to reject me (technical description is following my message). As I don't like when a software rejects me, I spent time one this issue (I thought that it was my fault because it is a quite basic feature in the software). I finally successed to isolate the issue and send a kind of SOS/bug report to someone at OpenCascade.
This request cost us 2 units of support from our contract.
Then, one week after, they get back to us with a "There is a bug in Pipe algorithm.". OK, cool. I was a bit proud to find a bug in this kind of big software (for the courageus/crazy, the reason of the bug is : "This bug is caused by complex structure of the curve approximated from 14 (15) points (some discontinuities of derivatives of high levels). Such structure of the curve causes turbulence of the local coordinate system of section along the curve. That is why the algorithm can not build a pipe where the section is orthogonal to the curve in each point all along the curve.", obvious no ?). However, I was expecting a small patch which will fix the issue and a "thank for the bug report". Instead of this, I saw :
The bug fix production can be started after your confirmation.
Please note that the standard price of a query is 15 units of your support program.
OK, now, I know how they make cash (at least a part of it).
You submit what you think to be a bug, it costs you 2 units. They confirm that is a bug, you have to pay 15 units to get the fix. Otherwise, you have to wait for the new release planned whenitwillbeready.
I am not saying it is a bad solution (and I do understand why they do that ... it is called support) but it could be more respectful for the user who spent many time to isolate a bug and report it and consequently helped to improve their software...
(For their defense, they provided me a workaround for my issue).
A silly & boring PHP bug ...
November 3rd, 2005This morning, I received a emails telling me that there is a big problem on a website that I host. Users are not able to upload any image on the server. (Warning: imagejpeg(): Unable to access 474/10434/59107.jpg in /www/libs/functions.php on line 226) Weird... The problem is in a daily used function which has been running for years. The only recent changed was the migration from v4.4.0 => v4.4.1 of PHP few days ago.
Because of the time difference, I only saw this problem when I woke up this morning. And fortunately, Julien has been able to find a temporary workaround... By disabling the safe mode... Dirty but it fixes the problem.
In the first place, I thought it was a change in the default configuration of PHP but I received a other email about the same kind of problems. Let's see the bug tracker of PHP... Ok, I am not the first one who has this issue.
http://bugs.php.net/bug.php?id=35060
http://bugs.php.net/bug.php?id=35071
One of the workaround that I found in this bug report is to make a touch() before calling the imagejpeg() function... Almost worster than the safe mode fix as I use it everywhere.
And I saw that Sniper is considering this as a feature (this is not a bug but a feature). Well, I don't see the point of touching a file before creating it after but well...
And people are complaining about this. Like this message :
Changing the way functions work within a minor update (version+=0.0.1) is an irresponsible way of maintaining software. This bug (please don't call it a "feature") caused a lot of trouble on our servers.
And I don't think that the way Sniper is any answering really help in the first bug report.
However, it seems that he considers this as a bug in the second bug report. The modification here shows it : http://cvs.php.net/php-src/ext/gd/php_gd.h (details here : http://cvs.php.net/diff.php/php-src/ext/gd/php_gd.h?r1=1.59.2.1&r2=1.59.2.2&ty=u).
Now, let's see if they are going to release a 4.4.1.1 version or we will stay with a safe_mode=off for a little while...
Edit : Comments closed. Thank you spammers.
Bug fixes admin & dev
November 2nd, 2005Three small problems at work/personnal today.
I had to update the kernel of my boss's computer (running Ubuntu) in order to change an include.h into the GNU/Linux kernel (no more modification in the kernel). Then, I rebooted the computer but the data partition was not mounted. Getting stuff like :
root@scully:/# mount /data/
mount: /dev/hdb1 already mounted or /data busy
Of course, hdb1 is not mounted and /data is not busy (fuser -v /data is your friend).After a few investigation, I found that evms is trying to access to the drive on boot and I guess it is not releasing the hard drive properly or something like that.
Nov 02 17:07:28 scully _5_ Engine: is_volume_change_pending: Change pending: Volume /dev/evms/hdb1 needs to be activated.
The dirty workaround is to launch evms AFTER the mount all options.
mv /etc/rcS.d/S27evms /etc/rcS.d/S99evmsBe carreful, this could cause side effects.
I had to debug an issue under the linux version of our softwares. Impossible to read big files (over 2 go).
Then, I created a fake file of 3 go and made a small program to reproduce the issue.
Here is the source :#include
void myRead(FILE * fichier){ /*lit le fichier caractere par caractere*/ char buf; int ret=1; if (fichier!=NULL) do { ret=fread(&buf,sizeof(char),1,fichier); printf("%c",buf); }while(!feof(fichier)); } int main () { FILE *myFile = fopen( "bigfile","r" ); if (myFile!=NULL) { myRead(myFile); }else{ printf("myFile not opened"); } return 0; } Amazing, isn't it ?
When I run this program (after tsize testsize.cpp), I only get a myFile not opened.
Launching again this software with strace and I can see in the middle of the dump a :
open("bigfile", O_RDONLY) = -1 EFBIG (File too large)After a few links, I finally found the solution :
Add at the beginning of the source (before some includes) these three lines
#define _FILE_OFFSET_BITS 64
=> defines which interface will be used by default
#define _LARGEFILE64_SOURCE
=> permits the use of 64 bits functions
#define _LARGEFILE_SOURCE
=> permits the use of fseeko() and ftello()
Of course, it is possible to specify these define in the g++ command line like that : g++ -D_FILE_OFFSET_BITS=64 -o testsize testsize.cpp-
 Last but not least (I like this expression), an trick avoid stealer to make a direct link to one of your image on their website and wasting your bandwith. Personally, I don't care. I have plenty of bandwith and it represents a small part of the current traffic.
Last but not least (I like this expression), an trick avoid stealer to make a direct link to one of your image on their website and wasting your bandwith. Personally, I don't care. I have plenty of bandwith and it represents a small part of the current traffic.
However, I had to fix this problem for a website which offers legal mp3 & avi.
The trick consists of using mod_rewrite. It checks the referent and if it is not from the official website and that it is trying to reach a file with a specific extension (mp3 and so on), we redirect the navigator to an other URL.Just put this few lines into your .htaccess and it should do it (if you have access to mod_rewrite for your website) :
DirectoryIndex index.php RewriteEngine On # Rewrite Rules for files # if the referent is not empty RewriteCond %{HTTP_REFERER} !^$ # if the domain is not our RewriteCond %{HTTP_REFERER} !^(.*)(domain.com|domain.com.au)(.*)$ # if the extension if in the list RewriteCond %{REQUEST_URI} \.(mp3|wmv|wma|zip|avi|mpg)$ [NC] # Redirect to an URL RewriteRule ^(.*)$ http://sylvestre.ledru.info/ [L]Pretty simple isn't it ?

PS : why this image ? Well, this post is too technical... This picture has been taken last week end in Sealers Cove in Wilson 's Promontory in Victoria.
Edit : comments are closed. Thank you spammer.
L'importance de l'optimisation
Novembre 1st, 2005La fréquentation... On l'espère sur chacun des sites que l'on lance. Une des contre partie est l'accroissement de ressources utilisées. J'avais pas réalisé comment un trafic très important peut impacter rapidement un serveur via un site mal optimisé.
Durant ces dernières semaines, j'en avais marre de voir le processeur de [i]mes[/i] serveurs de plus en plus utilisés par quelques sites. Prenant le kangourou par les oreilles, j'ai décidé de m'attaquer aux problèmes... Avec, en toute modestie, succès. Voila donc les deux cas réels que j'ai du traiter ces derniers temps :
* Le premier exemple est le passage à la dernière version (dawn - 0.9.1) de b2evolution.
Mon blog et le blog groupé (http://blog.jovialyteam.com) sont hébergés sur le même serveur. Ils se font spammer à une moyenne de 2/3 connexions HTTP à la seconde pour des fake referents vers des sites porno ou de médicaments de tout genre. Malgré les protections, les spammeurs trouvent toujours des contournements et leurs robots spammeurs se connectent toujours sur le site et entrainent le traitement PHP et SQL du site.
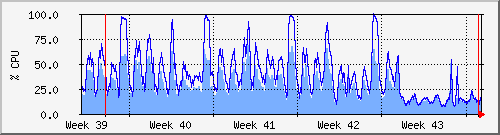
J'ai donc mis à jour b2evolution et l'impact sur les performances est phénoménal comme on peut le voir sur ce graphe :

Avant et après la maj de b2evolution sur une semaine
(les piques sont normaux et causés par un autre programme).
On voit clairement l'impact... Impact qui se voit aussi sur la base de données en terme de requêtes SQL et donc en utilisation du serveur SQL.
Comme quoi, bien choisir son logiciel est important et malheureusement, il est très difficile d'évaluer ce critère dans le monde réel...
* Deuxième exemple. J'ai développé pour l'association australia-australie.com un système de carnet de voyage http://www.carnets.australia-australie.com/ sur l'Australie. A l'époque, je ne pensais pas que ça prendrait autant d'importance donc les questions de performance n'avaient pas été un point crutial dans le développement du site mais voila, c'est devenu un succès en terme d'utilisation et de fréquentation causant ainsi un ralentissement notable dans l'accès au site. J'ai donc regardé le code (que je ne touchais plus depuis quelques temps vu que je développe la nouvelle version ...) et je me suis rapidement aperçu que j'avais zappé de créer les index sur les clés secondaires (je sais, j'ai honte).
Par exemple, les commentaires sur les carnets fonctionnent en arbre et du à la version de MySQL à l'époque, je dois faire une requête par branche dans une fonction récursive. Autant dire quelque chose qui tire sur un carnet à forte fréquentation avec beaucoup de commentaires.
Je l'ai donc généré les index à tous les endroits nécessaires (enfin, tout ceux que j'ai vu) et la rapidité a été vraiment augmentée et l'utilisation processeur réduite par un facteur énorme... (J'ai l'impression de vendre une lessive en disant ça).
Evolution sur un mois avant et apres les index
Moralité... utiliser les index de base de données...
Ceci dit, une chose que je déplore dans les applications web comme par exemple mediawiki, c'est la non ou pauvre utilisation des caches. Par cache, j'entend conserver une copie de la page web générée pour la reservir directement si le contenu n'a pas changé... Evitant ainsi tout le processus de génération classique (boucles, traitement, connexion sql...). Au contraire, ils refont tous le processus à chaque connexion sachant pertinemment que le ratio (nouvelle page devant être généré)/(page déjà généré) est toujours à considérer... L'utilisation d'un moteur de template comme smarty réglant ce genre de problème (j'avoue que c'est long, parfois complexe et prévu depuis le début ou dans une refonte mais on y gagne tellement ...). A la place, on préfère demander de nouveaux serveurs...
Le Spam tue !
Septembre 3rd, 2005J'administre le serveur sur lequel tourne mon blog. Il héberge pas mal de sites. Aucun ne générant des trafics délirant mais des sites de trafic moyen.
En autre sur ce blog, c'est entre 400 et 1200 connexions par jour. Il y a aussi quelques autres blogs qui générent entre 200 et 500 connexions par jour. Bref, rien d'énorme. Ceci dit, dans ces chiffres se cachent les robots des Spammeurs qui viennent pourrir les commentaires, les référents et les trackballs. Les robots vont simuler les interventions humaines. C'est-à-dire qu'ils vont consulter les pages HTML et mettre le texte et valider les formulaires. Bien sur, pour chaque page générée pour un robot, le serveur doit parser et traiter les pages PHP, lancer les requêtes SQL, etc d'où une surcharge du serveur inutile.
Suite au commentaire de Ralphy, j'ai testé une fonction (BlockUntrustedVisitors() qui en plus a le bon gout de ne pas être limité à b2evolution) qui se rajoute dans le code de b2evolution. Celle-ci se charge de refuser l'accès au site dès la connexion (c'est-à-dire avant le gros du traitement PHP) les robots hébergés sur des IPs connues comme étant détournées (essentiellement des PC sous Windows bourrés de Spywares).
Bref, j'ai donc rajouté cette fonction et j'ai été très surpris de voir l'impact évident que ça a eu sur le serveur.
Ce graphe (généré par MRTG à partir d'un script qui utilise le programme sar fourni par sysstat) montre l'utilisation processeur avant l'ajout de la fonction et après (vers 7 heure du matin).
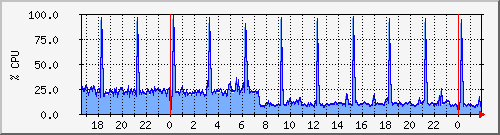
Utilisation CPU avant et après l'ajout de la fonction
On voit facilement une diminution de plus de moitié de l'utilisation processeur (25 % d'utilisation à 8/9 %, les piques étant le programme de génération des stats - donc rien à voir) alors que le traitement SQL n'est même pas réalisé sur ce serveur mais sur un autre en LAN.
Par là, je ne veux pas montrer que b2evolution est lent, ça n'est pas le point. C'est surtout pour montrer l'impact économique que le SPAM a actuellement sur Internet car pour être capable de gérer cet utilisation anormale, il faut mettre à jour les serveurs ou en rajouter ... (la modification du code n'étant pas toujours possible). J'en fait déjà fait la désagrable expérience avec les serveurs mail tous les jours depuis des années mais je n'avais pas réalisé qu'elle touchait tant les serveurs web ...