Catégorie: "Administration"
Rebuild of Debian using Clang 3.4
Mars 21st, 2014Using the AWS donation, David Suarez and myself have been able to rebuild the whole archive with Clang 3.4.
The rebuild has been done January 10th but, with my new job, I did not find the time to publish the result.
Releases after releases, the results are getting better and better.
Currently, 2193 packages in the archive are failing to build from source.
That is roughly the same number of build failures as with the precedent rebuild with Clang 3.3.
However, this is good news for two reasons:
* the number of new packages in Debian increased (18854 at time of the 3.3 release, 21204 for the 3.4)
* clang 3.4 has more checks and error detections.
I also started to update clang to make it closer to gcc. For example, I transformed wrong usage of -O (> 6) error to be treated as regular warning.
However, a critical bug has emerged during this release. When using -D_FORTIFY_SOURCE=2 (which is the case of many Debian packages), the binaries produced freeze (infinity loop in the ASM). This has been reported upstream as bug 16821 and concerns about 150 packages (including Firefox, gcc, LLVM, etc). Hopefully, this will be fixed in 3.5 (this is unlikely for 3.4.1).
About the new build failures, now, Clang triggers an error (or warning + -Werror) on:
* Wrong usage of the default argument (should be done in the definition)
16 occurrences
* Usage of C++11 feature without the appropriate argument
7 occurrences
* Unused static const declaration
5 occurrences
* Recursive template instantiation exceeded
4 occurrences
* Defitinion of a builtin function
3 occurrences
* Read-only variable is not assignable
2 occurrences
By the way, I proposed a Google Summer of Code Project to work faster on a support of Debian built by Clang. As requirements, I asked students to fix some bugs, they already did a great job.
-bash: /bin/ls: No such file or directory
September 19th, 2006If you have done a mistake/lost the /lib/ directory. Example :
mv lib lib.
And you are stuck without anything working :
# ls
-bash: /bin/ls: No such file or directory
Don't waste your time in a reinstallation, there is a trick :
/lib./ld-linux.so.2 --library-path /bin/ mv /lib. /lib/
It invokes the program loader directly and the problem will be fixed (of course, you can use this command to call many programs).
Monitoring a specific virtualhost apache
December 29th, 2005Monitoring apache quite easy. There are plenty of solutions to do that. When it comes to monitore virtualhost one by one, it starts to be difficult. Of course, there is always the solution of using stats softwares but usually, it is not really time and doesn't give a quick and efficient overview.
Here comes mod_watch. A quite old module for Apache (1.3 & 2.0). Basically it monitores the incoming/outcoming traffic and the requests.
There is no debian package for this module. However, it is very easy to install.
apt-get install apache-dev
tar -zxvf mod_watch318.tgz
cd mod_watch-3.18
make install
Edit /etc/apache/modules.conf
And add in it :
LoadModule watch_module /usr/lib/apache/1.3/mod_watch.so
Edit /etc/apache/httpd.conf
Add :
<IfModule mod_watch.c>
# Allows the URL used to query virtual host data:
#
# http://www.snert.com/watch-info
#
<location /watch-info>
SetHandler watch-info
Order allow,deny
Allow from hostname
</location>
# Intended for debugging and analysis of shared memory
# hash table and weenie files:
#
# http://www.snert.com/watch-table
#
<location /watch-table>
SetHandler watch-table
Order allow,deny
Allow from hostname
</location>
</IfModule>
Stop & start apache (not a restart)
/etc/init.d/apache stop && /etc/init.d/apache start
For each virtualhost, you should be able to see a line containting this kind of data :
sylvestre.ledru.info 49 0 499775 39 9 1 0.000 136656176 3221223448
This means :
| sylvestre.ledru.info | target name |
| 49 | uptime in second |
| bytes received from requests | |
| 499775 | bytes sent |
| 39 | number of requests received |
| 9 | number of documents sent |
| 1 | number of active connections |
| 0.000 | approx. 5 minutes average of bytes sent per second |
| 136656176 | bytes sent during the current 5 minutes period |
| 3221223448 | start time() of the current 5 minutes period |
This data are meant to be retrieve by MRTG thought the mod_watch client in order to produce graphs, ie :
# ./mod_watch.pl http://sylvestre.ledru.info/watch-info
0
2012653
11.31
sylvestre.ledru.info
This returns the number of bytes out.
Or
# ./mod_watch.pl -f ifRequests,ifDocuments http://sylvestre.ledru.info/watch-info
241
80
13.02
sylvestre.ledru.info
This returns the number of requests and documents.
Finally, as the developer knows that ITs are lazy, he made a script which will automatically create an MRTG configuration file from the apache configuration (I made a small patch in order to monitore also the documents/requests with this script and fixes a bug with mrtg indexmaker)
wget http://sylvestre.ledru.info/howto/mod_watch/patch_apache2mrtg.diff
patch < patch_apache2mrtg.diff
Add Workdir: /path/to/www/ for the output dir
./apache2mrtg.pl /etc/apache/httpd.conf > /etc/vhosts_mrtg.cfg
Caution ! apache2mrtg.pl will parse ALL the virtualhost. Even those with htaccess login/password and then won't be able to access to the watch-info files. Remove them from the vhosts_mrtg.cfg file.
There is many solution to customize the value & data. Check out the documentation here : http://www.snert.com/Software/mod_watch/.
Advantages :
* Quite easy to install, configure & maintain
* Quite fast
* Make very easy the task to find which virtualhost takes all the bandwith.
Disavantages :
* Impact on the performance ?
* No monitoring of CPU / Memory
* Based on headers (ie, if I start a download of 200 mo and I stop at the beginning, it will count 200 mo... Problem Described here)
Next tasks :
* Patch the software to add CPU & Memory monitoring PER virtualhost or find a module which does that.
* Find a way to fix the headers issue.
* Add the total bytes transferts
Edit : Comments closed. Thank you spammers !
Bug fixes admin & dev
November 2nd, 2005Three small problems at work/personnal today.
I had to update the kernel of my boss's computer (running Ubuntu) in order to change an include.h into the GNU/Linux kernel (no more modification in the kernel). Then, I rebooted the computer but the data partition was not mounted. Getting stuff like :
root@scully:/# mount /data/
mount: /dev/hdb1 already mounted or /data busy
Of course, hdb1 is not mounted and /data is not busy (fuser -v /data is your friend).After a few investigation, I found that evms is trying to access to the drive on boot and I guess it is not releasing the hard drive properly or something like that.
Nov 02 17:07:28 scully _5_ Engine: is_volume_change_pending: Change pending: Volume /dev/evms/hdb1 needs to be activated.
The dirty workaround is to launch evms AFTER the mount all options.
mv /etc/rcS.d/S27evms /etc/rcS.d/S99evmsBe carreful, this could cause side effects.
I had to debug an issue under the linux version of our softwares. Impossible to read big files (over 2 go).
Then, I created a fake file of 3 go and made a small program to reproduce the issue.
Here is the source :#include
void myRead(FILE * fichier){ /*lit le fichier caractere par caractere*/ char buf; int ret=1; if (fichier!=NULL) do { ret=fread(&buf,sizeof(char),1,fichier); printf("%c",buf); }while(!feof(fichier)); } int main () { FILE *myFile = fopen( "bigfile","r" ); if (myFile!=NULL) { myRead(myFile); }else{ printf("myFile not opened"); } return 0; } Amazing, isn't it ?
When I run this program (after tsize testsize.cpp), I only get a myFile not opened.
Launching again this software with strace and I can see in the middle of the dump a :
open("bigfile", O_RDONLY) = -1 EFBIG (File too large)After a few links, I finally found the solution :
Add at the beginning of the source (before some includes) these three lines
#define _FILE_OFFSET_BITS 64
=> defines which interface will be used by default
#define _LARGEFILE64_SOURCE
=> permits the use of 64 bits functions
#define _LARGEFILE_SOURCE
=> permits the use of fseeko() and ftello()
Of course, it is possible to specify these define in the g++ command line like that : g++ -D_FILE_OFFSET_BITS=64 -o testsize testsize.cpp-
 Last but not least (I like this expression), an trick avoid stealer to make a direct link to one of your image on their website and wasting your bandwith. Personally, I don't care. I have plenty of bandwith and it represents a small part of the current traffic.
Last but not least (I like this expression), an trick avoid stealer to make a direct link to one of your image on their website and wasting your bandwith. Personally, I don't care. I have plenty of bandwith and it represents a small part of the current traffic.
However, I had to fix this problem for a website which offers legal mp3 & avi.
The trick consists of using mod_rewrite. It checks the referent and if it is not from the official website and that it is trying to reach a file with a specific extension (mp3 and so on), we redirect the navigator to an other URL.Just put this few lines into your .htaccess and it should do it (if you have access to mod_rewrite for your website) :
DirectoryIndex index.php RewriteEngine On # Rewrite Rules for files # if the referent is not empty RewriteCond %{HTTP_REFERER} !^$ # if the domain is not our RewriteCond %{HTTP_REFERER} !^(.*)(domain.com|domain.com.au)(.*)$ # if the extension if in the list RewriteCond %{REQUEST_URI} \.(mp3|wmv|wma|zip|avi|mpg)$ [NC] # Redirect to an URL RewriteRule ^(.*)$ http://sylvestre.ledru.info/ [L]Pretty simple isn't it ?

PS : why this image ? Well, this post is too technical... This picture has been taken last week end in Sealers Cove in Wilson 's Promontory in Victoria.
Edit : comments are closed. Thank you spammer.
L'importance de l'optimisation
Novembre 1st, 2005La fréquentation... On l'espère sur chacun des sites que l'on lance. Une des contre partie est l'accroissement de ressources utilisées. J'avais pas réalisé comment un trafic très important peut impacter rapidement un serveur via un site mal optimisé.
Durant ces dernières semaines, j'en avais marre de voir le processeur de [i]mes[/i] serveurs de plus en plus utilisés par quelques sites. Prenant le kangourou par les oreilles, j'ai décidé de m'attaquer aux problèmes... Avec, en toute modestie, succès. Voila donc les deux cas réels que j'ai du traiter ces derniers temps :
* Le premier exemple est le passage à la dernière version (dawn - 0.9.1) de b2evolution.
Mon blog et le blog groupé (http://blog.jovialyteam.com) sont hébergés sur le même serveur. Ils se font spammer à une moyenne de 2/3 connexions HTTP à la seconde pour des fake referents vers des sites porno ou de médicaments de tout genre. Malgré les protections, les spammeurs trouvent toujours des contournements et leurs robots spammeurs se connectent toujours sur le site et entrainent le traitement PHP et SQL du site.
J'ai donc mis à jour b2evolution et l'impact sur les performances est phénoménal comme on peut le voir sur ce graphe :

Avant et après la maj de b2evolution sur une semaine
(les piques sont normaux et causés par un autre programme).
On voit clairement l'impact... Impact qui se voit aussi sur la base de données en terme de requêtes SQL et donc en utilisation du serveur SQL.
Comme quoi, bien choisir son logiciel est important et malheureusement, il est très difficile d'évaluer ce critère dans le monde réel...
* Deuxième exemple. J'ai développé pour l'association australia-australie.com un système de carnet de voyage http://www.carnets.australia-australie.com/ sur l'Australie. A l'époque, je ne pensais pas que ça prendrait autant d'importance donc les questions de performance n'avaient pas été un point crutial dans le développement du site mais voila, c'est devenu un succès en terme d'utilisation et de fréquentation causant ainsi un ralentissement notable dans l'accès au site. J'ai donc regardé le code (que je ne touchais plus depuis quelques temps vu que je développe la nouvelle version ...) et je me suis rapidement aperçu que j'avais zappé de créer les index sur les clés secondaires (je sais, j'ai honte).
Par exemple, les commentaires sur les carnets fonctionnent en arbre et du à la version de MySQL à l'époque, je dois faire une requête par branche dans une fonction récursive. Autant dire quelque chose qui tire sur un carnet à forte fréquentation avec beaucoup de commentaires.
Je l'ai donc généré les index à tous les endroits nécessaires (enfin, tout ceux que j'ai vu) et la rapidité a été vraiment augmentée et l'utilisation processeur réduite par un facteur énorme... (J'ai l'impression de vendre une lessive en disant ça).
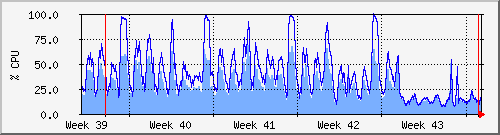
Evolution sur un mois avant et apres les index
Moralité... utiliser les index de base de données...
Ceci dit, une chose que je déplore dans les applications web comme par exemple mediawiki, c'est la non ou pauvre utilisation des caches. Par cache, j'entend conserver une copie de la page web générée pour la reservir directement si le contenu n'a pas changé... Evitant ainsi tout le processus de génération classique (boucles, traitement, connexion sql...). Au contraire, ils refont tous le processus à chaque connexion sachant pertinemment que le ratio (nouvelle page devant être généré)/(page déjà généré) est toujours à considérer... L'utilisation d'un moteur de template comme smarty réglant ce genre de problème (j'avoue que c'est long, parfois complexe et prévu depuis le début ou dans une refonte mais on y gagne tellement ...). A la place, on préfère demander de nouveaux serveurs...